
はじめに
近年、多くの業界においてDXを進める企業が増加し、ビジネス上の重要な意思決定においてデータの活用と分析の需要はますます高まっていると感じています。
その手始めとして、データ分析用の基盤構築・整備が行われると思うのですが、その際の大変なことの1つとして、集計したいデータが複数のデータソースに存在し、それを定期的に集めてくることの実現ではないでしょうか。 弊社でも最近、データ分析基盤の整備を行いました。その際の上記課題感に対しては、記事タイトルにもあるように、「Fivetran x BigQuery x dbt」といったサービスを組み合わせて解決・実現しました。
なお、弊社のメインサービスは、在宅医療・介護業界向けの訪問スケジュールサービスなのですが、日々蓄積されていく訪問の結果データを元に、ビジネス上の次の一手に繋がるような指標にまとめ、見える化したZEST BOARDというサービスを最近リリースしました。ZEST BOARDを作る上でも、本分析基盤がもとになっています。
📢NEW RELEASE
— 株式会社ゼスト (@zest_inc) 2023年6月21日
新プロダクトの経営指標を見える化するツール、『ZEST BOARD』をリリース👏
ZEST BOARDをご活用いただき、経営指標を見える化することで、課題が明確になり、適切な打ち手がとれ、売上・採用力向上の実現に繋げることができます🌷
詳細はこちら↓https://t.co/HPrKceb00Q pic.twitter.com/nRsuffp0JN
Fivetranを使ったデータ基盤構築
まずはじめに Fivetranとは
- 自動でデータパイプラインを構築するSaaS型のクラウドサービス
- 様々なデータソースからデータを抽出し、データ同期先へのロードを自動化することが可能
- 主な構成要素としては、「Connectors」「Destinations」「Transformations」の3つ
Connectors: データソースの設定
- アプリケーション、データベース、ファイル、イベント、ファンクションからデータを抽出できるコネクターを300以上提供しており、実装が不要で、管理画面上で設定するだけ
- 提供されていないデータソースからデータを抽出したい場合、コネクターを作成することも可能
- 同期タイミングの設定が可能
※ コネクターに関しては、料金Planによって使用できるものとできないものがあるので要注意!!
Destinations: データ同期先の設定
- 主要なデータウェアハウスを網羅しており、実装が不要で、管理画面上で設定するだけ
Transformations: データ変換・加工
- データロード後に、データウェアハウスにて変換/加工処理を実施することが可能
- dbtを使用して、複雑な変換/加工を実行することが可能
- 実行タイミングの設定が可能
その他の機能としては、
- 各コネクタにて実行されたオペレーションログの確認やその通知が可能で、さらに他のログサービスと連携することでログ監視も可能
- 料金プランは以下の5つで、課金は月間アクティブ行数 (MAR、Monthly Active Rows) に対してのみ (Freeプランは無料で、上限50万MARまでの制約あり)

※ アクティブ行数とはBigQueryなどのデータ転送先に同期されたユニークなレコード数のことで、1 rowは1ヶ月に1度だけカウントされるため、データ量が多くても重複して課金対象になるということはありません。
※ 初回の同期は全て無料。
全体構成図
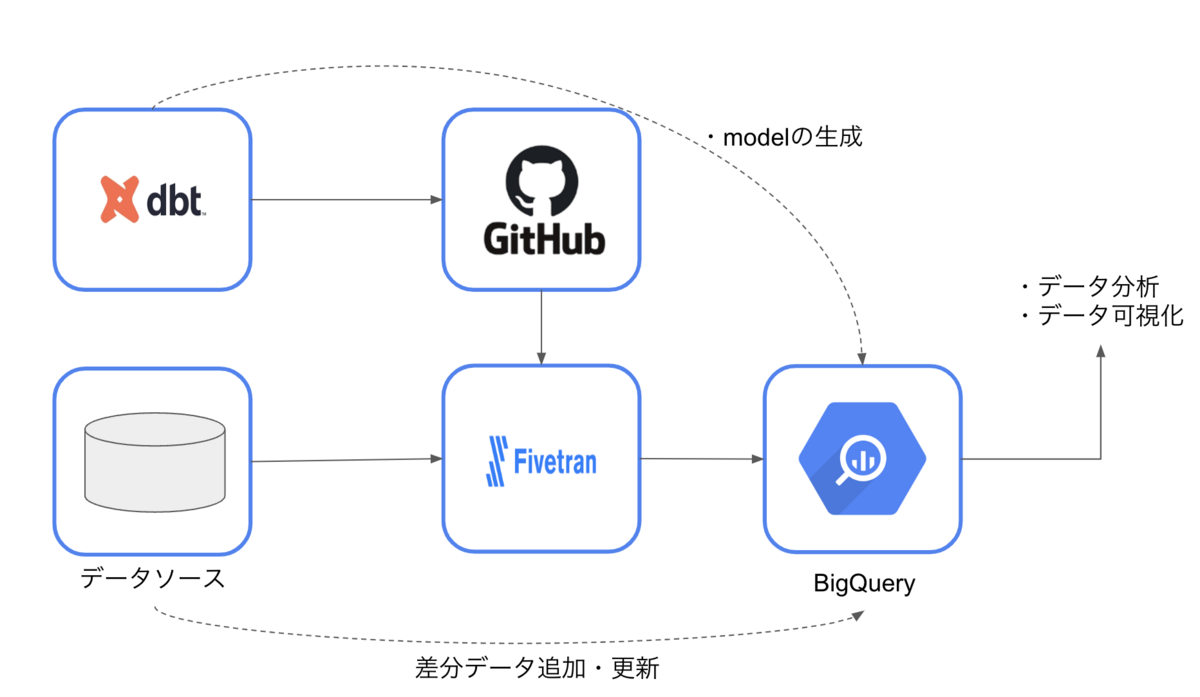
設定
ステップ1: データソースの準備
まずデータソース側のテーブル(よくある注文テーブルと顧客テーブル)を作成します。
※ 今回データソースは簡易化のために、CloudSQL(MySQL)を利用することにしましたが、通常Fivetranを使うケースというのは、データソースが異なるクラウドベンダーに存在するようなケースが多いと思います。
CREATE TABLE `orders` ( `id` VARCHAR(5) NOT NULL, `user_id` VARCHAR(5) NOT NULL, `item_id` VARCHAR(5) NOT NULL, `quantity` INT NOT NULL, PRIMARY KEY (`id`) ); INSERT INTO `orders` VALUES ('ORDR1', 'USER1', 'ITEM1', 10), ('ORDR2', 'USER2', 'ITEM1', 5), ('ORDR3', 'USER2', 'ITEM2', 20), ('ORDR4', 'USER3', 'ITEM2', 5), ('ORDR5', 'USER3', 'ITEM3', 12);
もう1つ、Fivetranで日本語の扱いがどうなるか確認するために、日本語テーブルも作っておきましょう。
CREATE TABLE `顧客` ( `顧客id` VARCHAR(5) NOT NULL, `顧客名` VARCHAR(20) NOT NULL, `住所` VARCHAR(20) NOT NULL, PRIMARY KEY (`顧客id`) ); INSERT INTO `顧客` VALUES ('USER1', 'user1', '東京都千代田区'), ('USER2', 'user2', '東京都杉並区'), ('USER3', 'user3', '東京都足立区');
データの準備が整ったので、FIvetranの設定をおこなっていきます。
ステップ2: FivetranにてDestinationsの設定
Destinations画面に遷移し、右上の 「Add destination」を押します。

以下のポップアップ画面が開くので、「Destination name」を入力して、「Add」を押します。

データソースの選択画面が表示されるので、データソースを選択して「Continue Setup」を押します(今回はBigQueryを使用するので、BigQueryを選択)。

GCPのProject IDを入力し、Fivetran指定のサービスアカウントに対して自身のGCPのIAMにて「BigQueryユーザー」と「ストレージ管理者」のロールを付与し、dbt用に「BigQuery データ編集者」のロールも付与します。
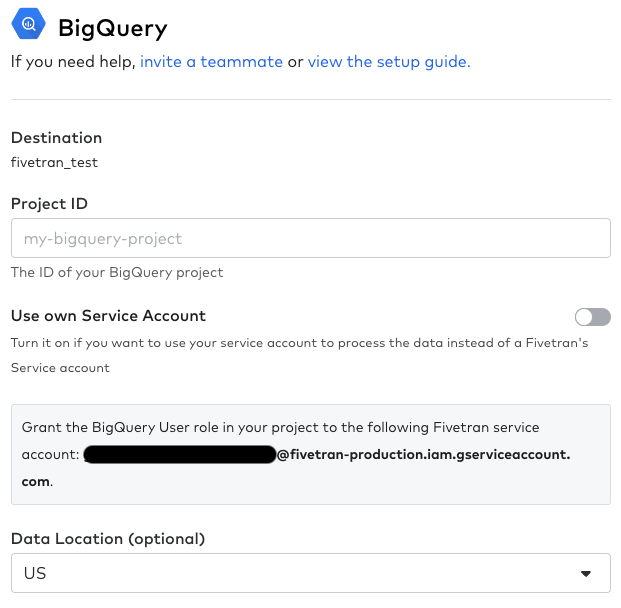
入力が完了したら「Save & Test」を押し、疎通が完了すると、以下のような画面が表示されます。

Destinationsの設定は以上です。
ステップ3: FivetranにてConnectorsの設定
Connectors画面に遷移し、右上の 「Add connector」を押します。

まずは先程作成した、destinationを選択します。

次はデータソース選択画面にて「Google Cloud MySQL」を選択します。

「Destination schema prefix」はそのままで、HostからPasswordまで入力します。

最後の「Please whitelist the following Fivetran IPs in your firewall.」はCloudSQLのインスタンス編集画面で承認済みネットワークに指定のIPを登録します。

入力が完了したら「Save & Test」を押し、疎通を完了させます。その後、以下の画面でSyncしたいDatabaseを選択し「Save & Continue」を押します。

同期実行と確認
初回同期をしていきましょう。以下の「Resume Initial Sync」を押すことで、開始されます。

実行が完了したら、BigQueryの画面で確認してみます。 すると、「fivetran_audit」「orders」「gu_ke」の3テーブルできていることが確認できます。

fivetran_audit
本テーブルは、Fivetranによって生成されるテーブルで、移行したデータの履歴(どのテーブルからいつ、何件、INSERT or UPDATEしたか)を管理します。
orders
次に、ordersテーブルです。データソースの内容が反映されていますね。

「fivetran_deleted」、「fivetran_synced」はFivetran側で生成されるカラムで、削除フラグと同期時間を表します。 データソース側でデータを削除し再度同期すると、同期先は削除されずにこのフラグがtrueとなるようです
gu_ke
最後に、謎のgu_keテーブルを見ていきましょう。 顧客テーブルのデータ内容が反映されていることが確認できますが、テーブル名とカラム名が謎の言葉に置き換わっています。

調べてみると、gukeというのは、顧客を表す中国語の「顾客」のピンイン(中国語のローマ字による表記法の一つ)表記だと分かりました。
どうやら日本語には対応しておらず、中国語のピンイン表記に変換されるようです。 日本語でDDL生成されている方は気をつけた方が良さそうですね。
※ ちなみにカタカナは「ユーザー」なら「yuza」と変換されました
※ FivetranのDocにNaming Ruleありますが、日本語については特に書かれていないようです
同期タイミングの設定
同期のタイミングに関しては、以下のSetup画面にて行います。

料金プランによって、可能な同期タイミングの設定が異なるので利用する前に確認しておくことをお勧めします。

ステップ4: FivetranにてTransformationsの設定
まずデータセットの構成として、以下のように定義します。
- google_cloud_mysql_test
- Fivetranにて同期したデータソース群
- google_cloud_mysql_staging
- seedで生成する商品テーブル(item)
- marts用に加工したテーブル群
- google_cloud_mysql_marts
- データ活用、分析、可視化のためのテーブル群
dbtを作成し、githubの適当なリポジトリに上げておきます。
ディレクトリ詳細
seeds配下
items.csv -------------------- ItemId,ItemName,Price ITEM1,りんご,150 ITEM2,みかん,100 ITEM3,なし,200
staging配下
sources.yml -------------------- version: 2 sources: - name: source schema: google_cloud_mysql_test tables: - name: orders - name: gu_ke stg_users.sql -------------------- {{ config(materialized = 'view') }} SELECT gu_ke_id AS UserId, gu_ke_ming AS UserName, zhu_suo AS Address FROM {{ source('source', 'gu_ke') }} stg_orders.sql -------------------- {{ config(materialized = 'view') }} SELECT id AS OrderId, user_id AS UserId, item_id AS ItemId, quantity AS Quantity FROM {{ source('source', 'orders') }}
marts配下
marts_orders.sql -------------------- {{ config(materialized = 'table') }} WITH final AS ( SELECT orders.OrderId, users.UserId, users.UserName, items.ItemId, items.ItemName, orders.Quantity, orders.Quantity * items.Price AS TotalPrice FROM {{ ref('stg_orders') }} as orders INNER JOIN {{ ref('stg_users') }} as users ON orders.UserId = users.UserId INNER JOIN {{ ref('items') }} as items ON orders.ItemId = items.ItemId ) SELECT * FROM final
deployment.yml
jobs: - name: run seed schedule: 0 12 * * * steps: - name: run seed command: dbt seed - name: dbt run For staging schedule: 0 12 * * * steps: - name: run command: dbt run --models staging - name: dbt run For marts schedule: 0 12 * * * steps: - name: run command: dbt run --models marts
dbt_project.yml
name: 'dbt_sample' version: '1.0.0' config-version: 2 profile: 'my_bigquery_db' model-paths: ["models"] seed-paths: ["seeds"] macro-paths: ["macros"] clean-targets: - "target" - "dbt_packages" - "logs" models: dbt_sample: staging: +schema: staging marts: +schema: marts seeds: dbt_sample: +schema: staging
Transformations画面での操作
Transformations画面に遷移し、先程作成したConnectorを選択し「Get started」を押します。
Fivetranからgitリポジトリにアクセスするためのpublic keyが提示されているので、Githubのsettingsから「Deploy keys」にて登録します。

RepositoryのURLとDefault Schema Nameは「google_cloud_mysql」とします。
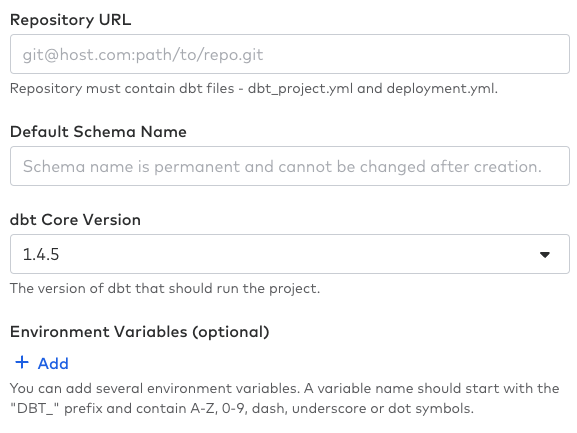
拡張オプションとしてTarget nameに「deployment.yml」を指定します。
deployment.ymlに実行コマンドを書いておくと、ディレクトリ単位での実行が可能なので便利です。

入力が完了したら「Save & Test」を押し、疎通を完了させます。

Tranformationsの画面に遷移すると以下のような一覧が表示されます。
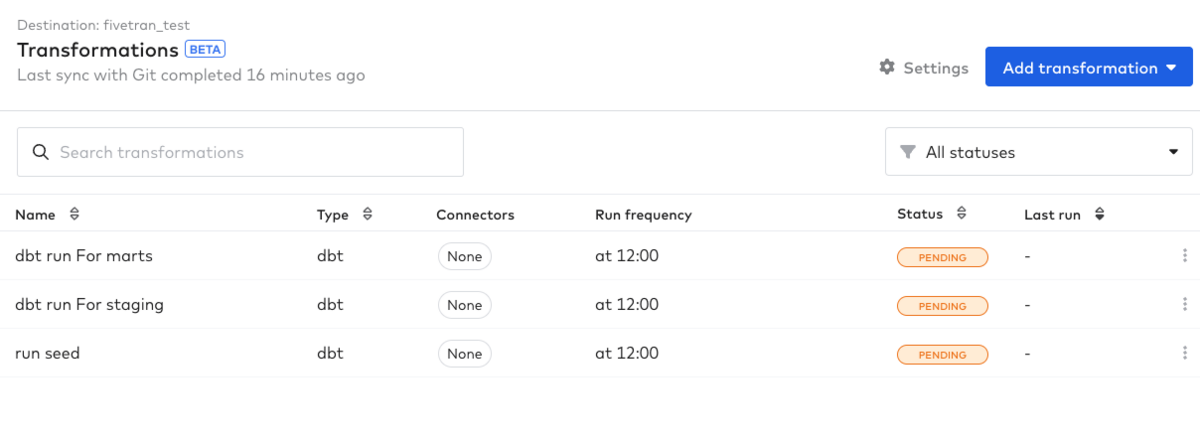
各Nameを選択し、右上の「Run Now」を押すと各dbtが実行されます。

動作確認
実行が完了したらBigQueryの画面で確認します。


marts_ordersテーブルもしっかりと作成されています。

これにて構築は完了となります。
まとめ
長々となりましたが、私が初見でFivetranを触った際は数時間で構築自体はできたので学習コストはかなり低いと思います。 技術選定時にいくつかGCPサービス(Data Fusion・Dataflowなど)やtroccoといったSaasサービスも触って検討しましたが、 学習コストの低さや導入コストの観点から一番最適と感じられたのが、このFivetranでした。 初回は無料で全データを同期してくれます。2回目以降は差分更新となるので、データベースへの負荷もそこまで大きくならないよう設計されているようです。 利用料金についてはMARでの課金のためデータソース側の増分度合いによっては不向きなパターンもあるかと思いますが、MARの増加に伴って料金も安くなっていくよう設計されているため、導入検討される際は導入前に料金試算しておいたほうが良さそうです。
弊社も導入したばかりではありますが、今後もFivetranの動向を追って情報発信していければと思います。